之前写过一篇文章介绍了容器环境下日志管理的原理机制:从 Docker 到 Kubernetes 日志管理机制详解,文章内容偏理论,本文在该理论的支撑下具体实践 Kubernetes 下基于 EFK 技术栈的日志收集,本文偏实践,要想全面了解 Kubernetes 下日志收集管理机制,最好还是两篇文章顺序阅读。
本文不仅限于介绍怎么在 Kubernetes 集群部署 EFK 组件,还涉及到其他相关话题:EFK 组件简介、Kubernetes 环境下为什么选用 EFK 优于 ELK 组件、Fluentd 简介、Fluentd 工作机制等等。本文结构如下:
- EFK 组件简介
- Kubernetes 环境下为什么选用 EFK 优于 ELK 组件
- Fluentd 简介
- Fluentd 工作机制
- Fluentd 配置的核心指令
- Kubernetes EFK 日志收集架构
- Kubernetes EFK 日志收集架构实践
EFK 组件简介

顾名思义,EFK 是 Elasticsearch、Fluentd、Kibana 三个开源软件组件的首字母缩写,EFK 是业界主流的容器时代日志收集处理的最佳解决方案。Fluentd 是一个日志收集器,负责从各个服务器节点抓取日志。Elasticsearch 是一个搜索存储引擎,可以存储 Fluentd 收集的日志,并提供查询服务。Kibana 是 Elasticsearch 的一个界面化组件,提供 UI 方式查询 Elasticsearch 存储的数据。三个组件组合起来工作就是 EFK,组件之间数据流是这样:Log 源(比如 Log 文件、k8s Pod 日志、Docker 日志驱动等等)—> Fluentd 收集 —> Elasticsearch 存储 —> Kibana UI 查看。
Kubernetes 环境下为什么选用 EFK 优于 ELK 组件
ELK 是 Elasticsearch、Logstash、Kibana 三个开源组件的缩写,可以看出和 EFK 的区别在于第二个字母,一个是 Logstash,一个是 Fluentd。
我们很早之前使用 ELK 技术栈收集云主机上部署的应用日志,每台虚拟主机部署一个 Logstash 实例收集应用程序目录日志,然后统一传输到一个 Logshtash 中央处理节点,处理后的数据存储到 Elasticsearch。这种方案虽然可以实现日志的统一收集处理,但是 Logstash 比较吃系统资源,基本上资源占用堪比一个 Java 微服务,一个简单的抓取节点就大概需要 1 GB 的内存,我们知道云主机的机器资源是非常昂贵的,所以这种方案对资源浪费比较大,不是很推荐。之前我们基于该 ELK 方案的日志收集大致架构图如下:收集大概 13 个微服务日志,其中 Logstash Server 端平均内存使用能达到 8GB +,显然 Logstash 比较重量级,对系统资源的消耗可见一斑。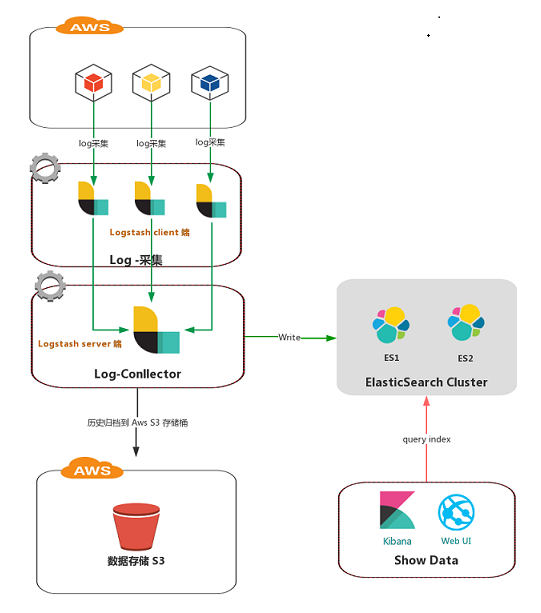
从上面的实践案例可以知道 ELK 技术栈的缺陷在于 Log 收集器 Logstash 比较重量级,对系统资源消耗比较大。那么有没有更加轻量级的替代方案呢?答案是有的,比如 Elastic 的 beats 家族的 Filebeat 就可以取代 Logstash 作为日志抓取器,还有 Fluentd 也可以作为 Logstash 替代品,Fluentd 也是本文要讲的重头戏。为什么我们选用 Fluentd 而不用 Filebeat 呢,个人认为 Fluentd 兼具日志抓取、收集、处理、轻量级的特性,拥有丰富的插件生态,是日志解决方案的神器。而 Filebeat 功能重点在于日志的抓取、轻量级,但是对于日志的处理功能不是很强大。
Fluentd 的轻量级体现在它本身核心代码是用 C 语言编写,更接近操作系统底层语言,所以一般性能是比较高的,据官方介绍 30~40 MB 内存就能处理 13000 日志事件/秒/核,由此可见其性能是多么强大,所以对比 Logstash 而言,用 30 MB 内存就能解决的问题当然选择 Fluentd 了。
Fluentd 简介
Fluentd 是一个开源的日志收集器,它统一了日志的收集和处理逻辑,多种不同来源的日志都可以通过 Fluentd 这个单一的工具统一收集,然后统一存储到单个或多个存储后端。
像很早之前没有类似 Fluentd 之类的工具的话,为了收集日志可能会有各种五花八门的方法(工具),比如:Shell 脚本分析日志文件、服务器 syslog 收集、rsync 定时同步,scp 拷贝日志文件到统一的存储服务器等等,这么做显然带来的问题是我们要维护各种日志收集端工具,由于各种工具使用上不统一,对整个日志系统的维护人员来说不亚于一场灾难。我们可以用一张图来描述这种复杂、错乱的场景: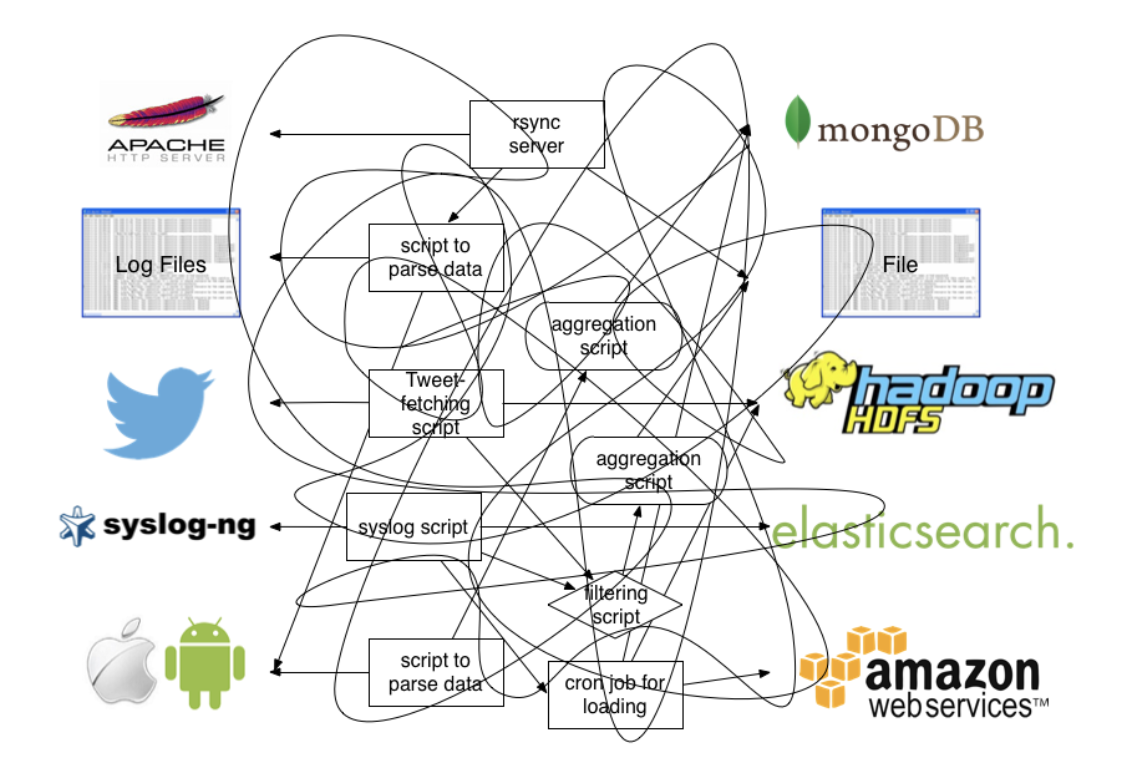
针对上述存在的问题,Fluentd 插件式架构很好地解决了该问题,所有数据收集端和存储端都可以通过 Fluentd 使用不同的插件统一起来,这么做带来的最大好处就是大大简化了日志收集的架构,整个架构都以 Fuentd 为核心,不再需要维护人员掌握、维护各种乱七八糟的小工具。上面复杂、错乱的数据收集架构就可以简化为以 Fluentd 为核心的简单架构了: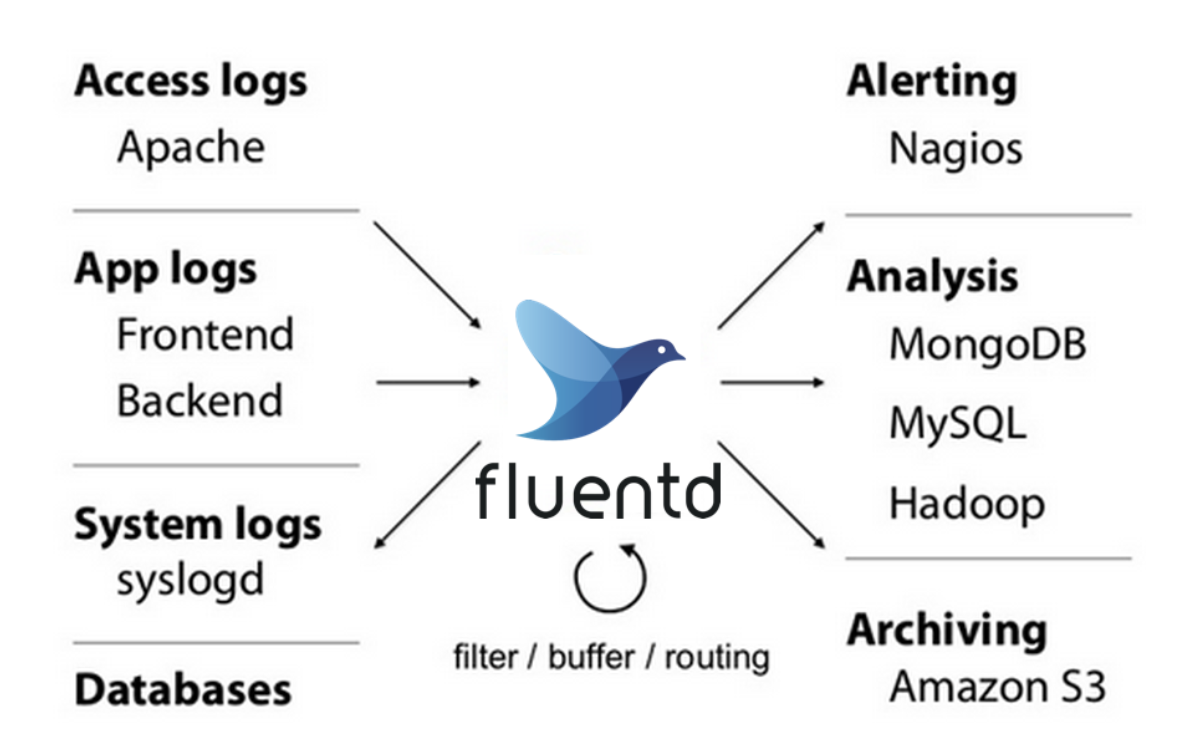
关于 Fluentd 更多的介绍见官方文档:https://docs.fluentd.org/ 。
Fluentd 工作机制
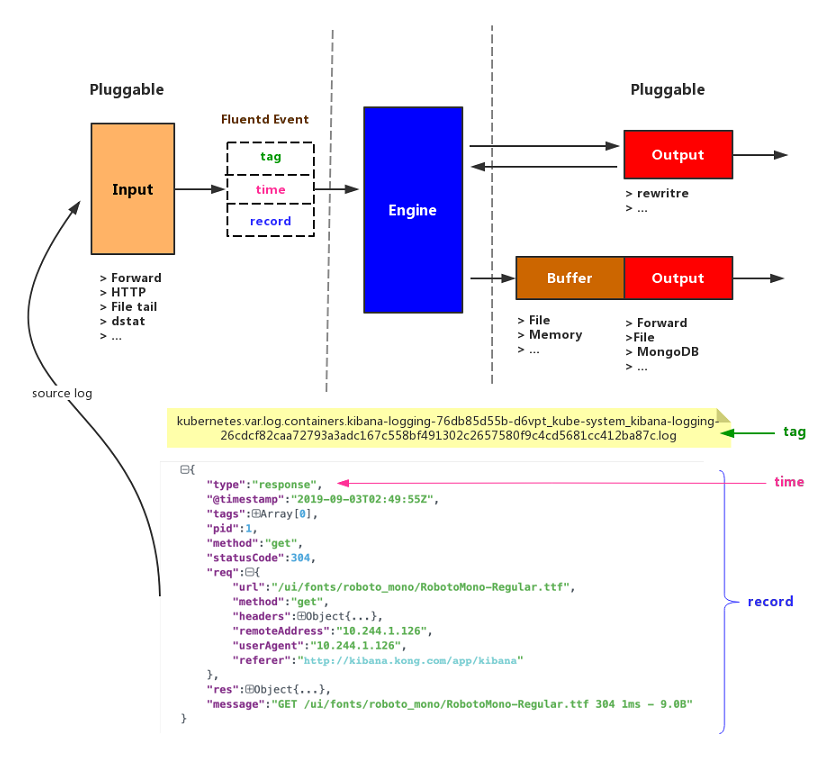
Fluentd 和其他日志收集器的工作原理类似,对数据的处理流程也分为三大阶段:收集—>处理、过滤—>输出。这三个处理阶段都有不同的插件支持,可以灵活组合。在 Fluentd 中事件是 整个数据流处理的基本单位,fluentd 的 input 插件每接收到一条日志都会将其封装成一个 fluentd 事件,然后发送给 fluentd 引擎处理,fluentd 引擎根据事件中包含的 tab 匹配不同的 filter 插件进行事件的处理,处理完后发送到 output 插件,output 插件根据事件中的 tag 匹配事件,将匹配到的事件发送到对应的后端。
Fluentd 事件由三部分组成:
- tag:
.分隔的字符串,供 fluentd 路由引擎路由使用; - time: 由输入插件指定的事件发生的时间戳,必须符合 Unix 时间格式;
- record: 日志内容;
Fluentd 配置的核心指令
上面简单介绍了下 Fluentd 对日志数据的处理流程,其是在这个流程中 Fluentd 的行为是通过其配置文件定义的,配置文件由一条条指令组成。下面是 Fluentd 配置文件的 6 大指令,是 Fluentd 配置的核心指令:
sourcedirectives determine the input sources.matchdirectives determine the output destinations.filterdirectives determine the event processing pipelines.systemdirectives set system wide configuration.labeldirectives group the output and filter for internal
routing@includedirectives include other files.
关于每条指令在具体配置文件中如何使用这里不再赘述,详情见:https://docs.fluentd.org/configuration/config-file
Kubernetes EFK 日志收集架构
之前介绍过 Kubernetes 日志管理机制:再 k8s 每个节点上,kubelet 会为每个容器的日志创建一个软链接,软连接存储路径为:/var/log/containers/,软连接会链接到 /var/log/pods/ 目录下相应 pod 目录的容器日志,被链接的日志文件也是软链接,最终链接到 Docker 容器引擎的日志存储目录:/var/lib/docker/container 下相应容器的日志。所以 /var/log 和 /var/lib/docker/container 目录是整个节点所有容器日志的统一存储地方,这就为 Fluentd 日志收集提供了很大的方便。
针对上述 k8s 日志管理机制,Kubernetes 官方给出了推荐的日志收集方案:以 DaemonsSet 的方式在 k8s 集群每个节点部署一个节点级的 Fluentd 日志收集器,Fluentd Pod 在启动时挂载了宿主机的 /var/log 和 /var/lib/docker/container 目录,因此可以直接对宿主机目录中的容器日志读取并传输到存储后端:Elasticsearch。然后 Kibana 和 Elasticsearch 对接即可实时查看收集到的日志数据。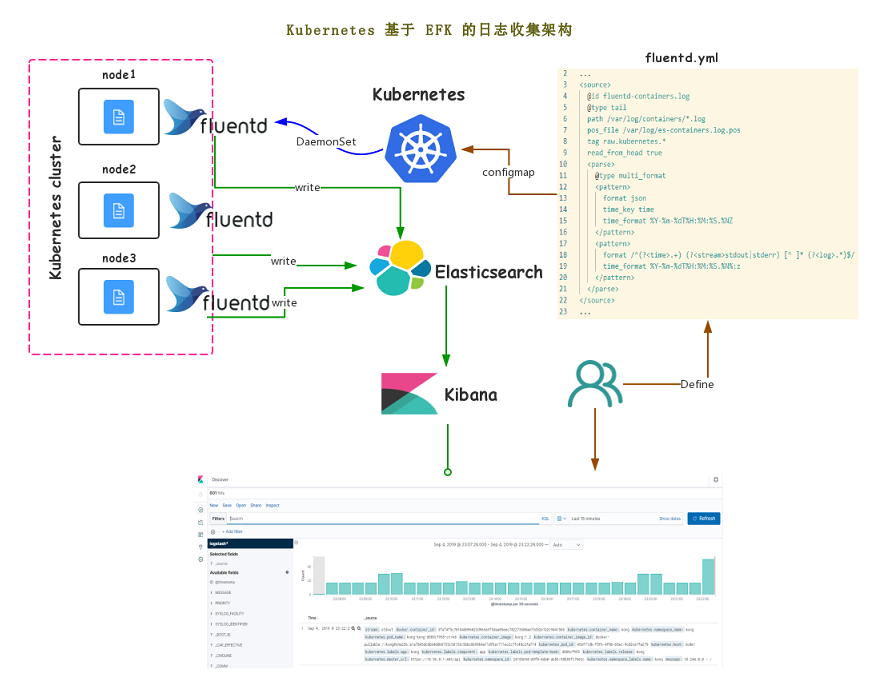
Kubernetes EFK 日志收集架构实践
上面介绍了 Kubernetes EFK 日志收集架构,本节基于该架构进行实践。我们使用 Kubernetes 官方提供的 EFK 组件 mainfest 文件进行部署,Github 仓库目录为:
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsearch
该目录下存储了 EFK 三大组件的部署 yaml 资源文件,有两点需要说明下:
- Elasticsearch 数据持久化:默认 EmptyDir 的方式,这种方式在 Pod 重新调度后数据会丢失,不过为了实验,所以在这里就不进行修改了,使用默认的即可;
- Kibana deployment 文件需要修改下:去掉 SERVER_BASEPATH 环境变量,要不然部署后访问会 404;
Kubernetes EFK 部署
进入 fluentd-elasticsearch 目录,执行:1
kubectl create -f .
查看 Pod 状态,确保每个组件启动成功,一般都会启动成功的,这里基本没什么坑。
Kibana 对外访问
接下来将 Kibana 服务从 Kubernetes 集群对外暴露出来,实现对外访问,我们使用 Kong 网关对外暴露服务。具体 Kong 网关在 Kubernetes 的使用在这里不再赘述,如想了解见这里:Kong 微服务网关在 Kubernetes 的实践。
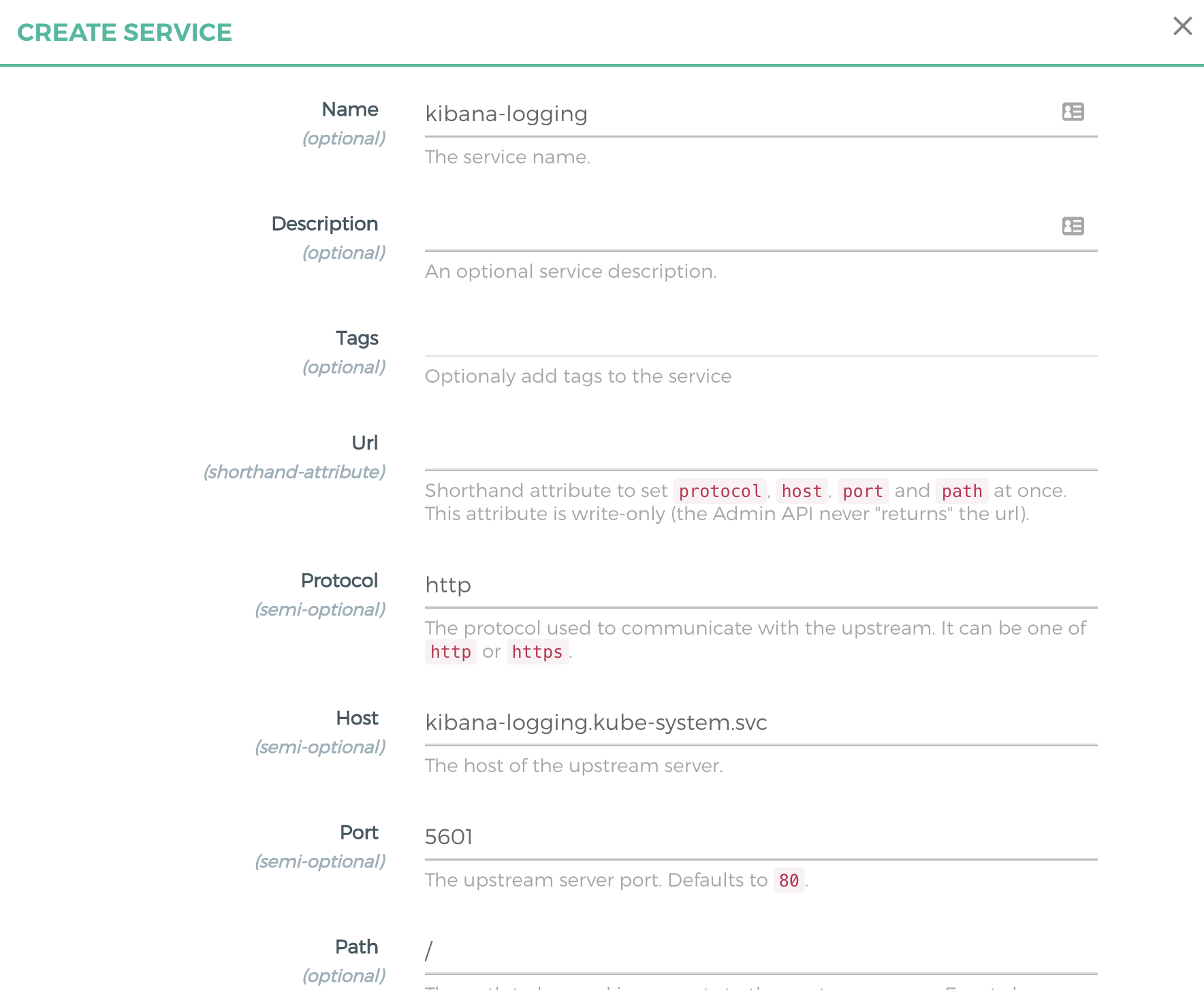
Konga 配置 Kibana 服务对外访问:
- 创建 kibana-logging Kong Service
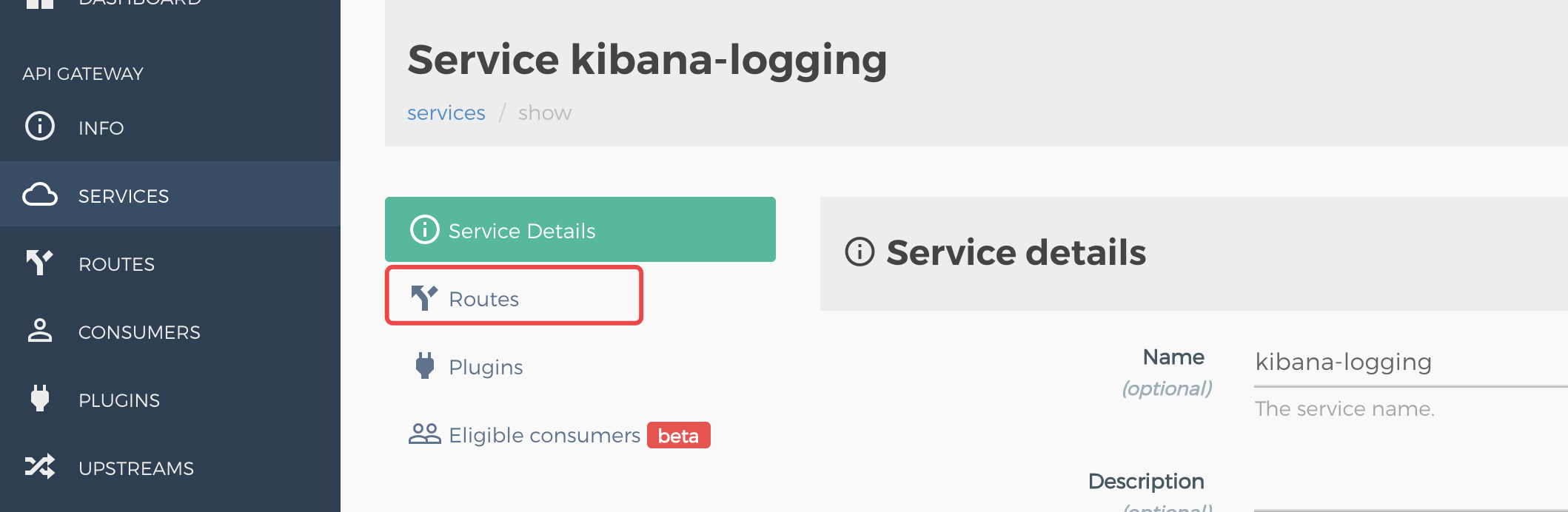
- 创建 Kong 路由到 kibana-logging Kong Service
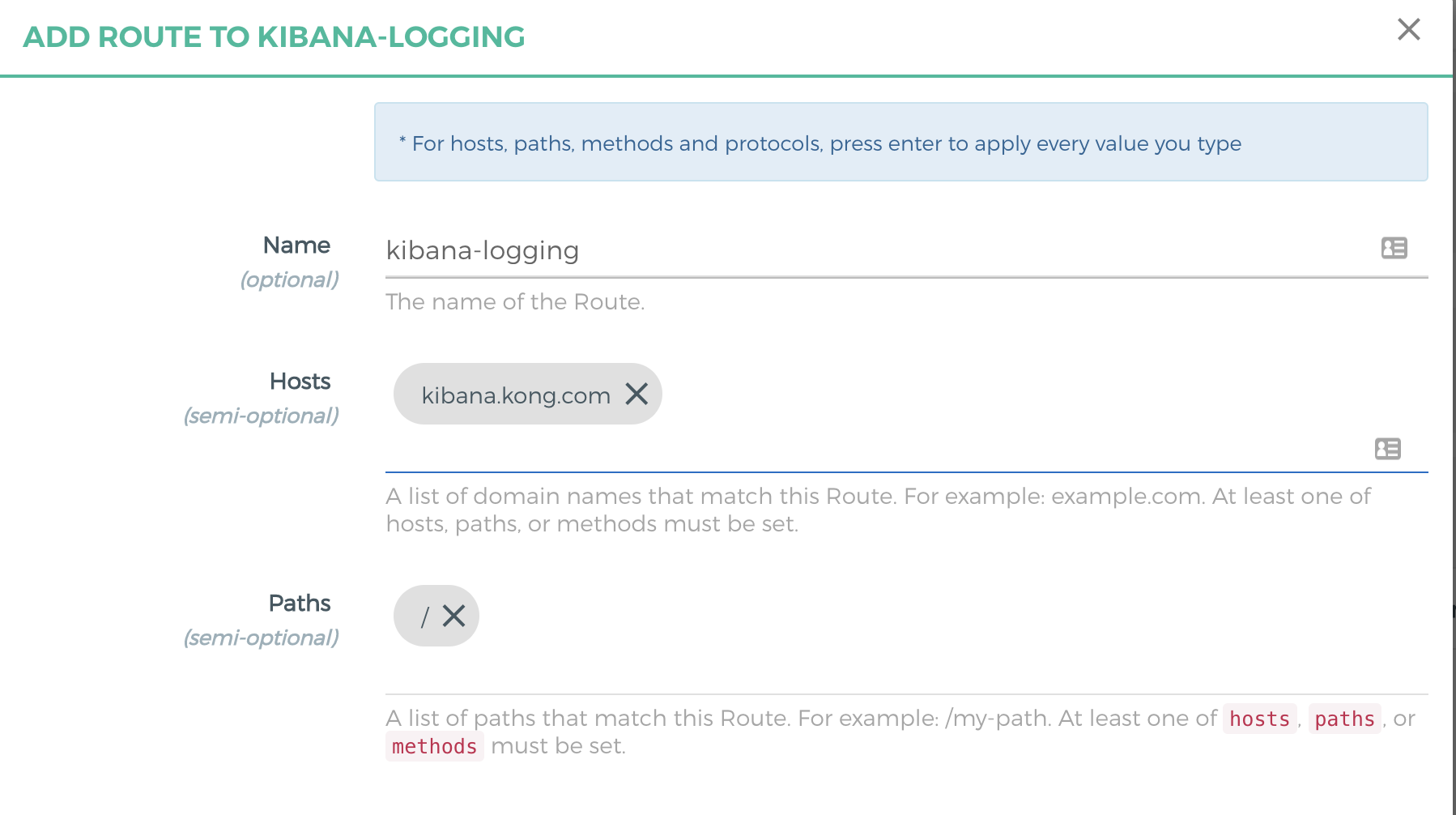
kibnana.kong.com 绑定 host 到集群节点 IP 即可访问查看收集的日志:
相关文档
https://kubernetes.io/docs/concepts/cluster-administration/logging/ | Kubernetes 日志架构
https://www.fluentd.org/architecture | What is fluentd?
https://docs.fluentd.org/quickstart/life-of-a-fluentd-event | Life of a Fluentd event