本文主要介绍使用 Prometheus 监控 Kubernetes 的最佳实践,借助 Prometheus Operator 和 Helm 快速完成 Kubernetes 集群的监控。
Prometheus Operator 是 SRE 的一种实践,一种新的软件类型,大大简化了在 Kubernetes 上部署、管理和运行 Prometheus 和 Alertmanager 集群,同时还保持 Kubernetes 原生配置项,和 Kubernetes 无缝贴合。
什么是 Prometheus?
Prometheus 是由 SoundCloud 开源的监控告警解决方案,从 2012 年开始编写代码,再到 2015 年 github 上开源以来,已经吸引了 9k+ 关注,以及很多大公司的使用;2016 年 Prometheus 成为继 k8s 后,第二名 CNCF(Cloud Native Computing Foundation) 成员。
作为新一代开源解决方案,很多理念与 Google SRE 运维之道不谋而合。比如 Operator 的概念:将复杂运维工作固化到 Operator 软件实体中。
Prometheus 主要功能
- 多维 数据模型(时序由 metric 名字和 k/v 的 labels 构成)。
- 灵活的查询语句(PromQL)。
- 无依赖存储,支持 local 和 remote 不同模型。
- 采用 http 协议,使用 pull 模式,拉取数据,简单易懂。
- 监控目标,可以采用服务发现或静态配置的方式。
- 支持多种统计数据模型,图形化友好。
Prometheus 核心组件
- the main Prometheus server which scrapes and stores time series data
- client libraries for instrumenting application code
- a push gateway for supporting short-lived jobs
- special-purpose exporters for services like HAProxy, StatsD, Graphite, etc.
- an alertmanager to handle alerts
- various support tools
Prometheus 架构
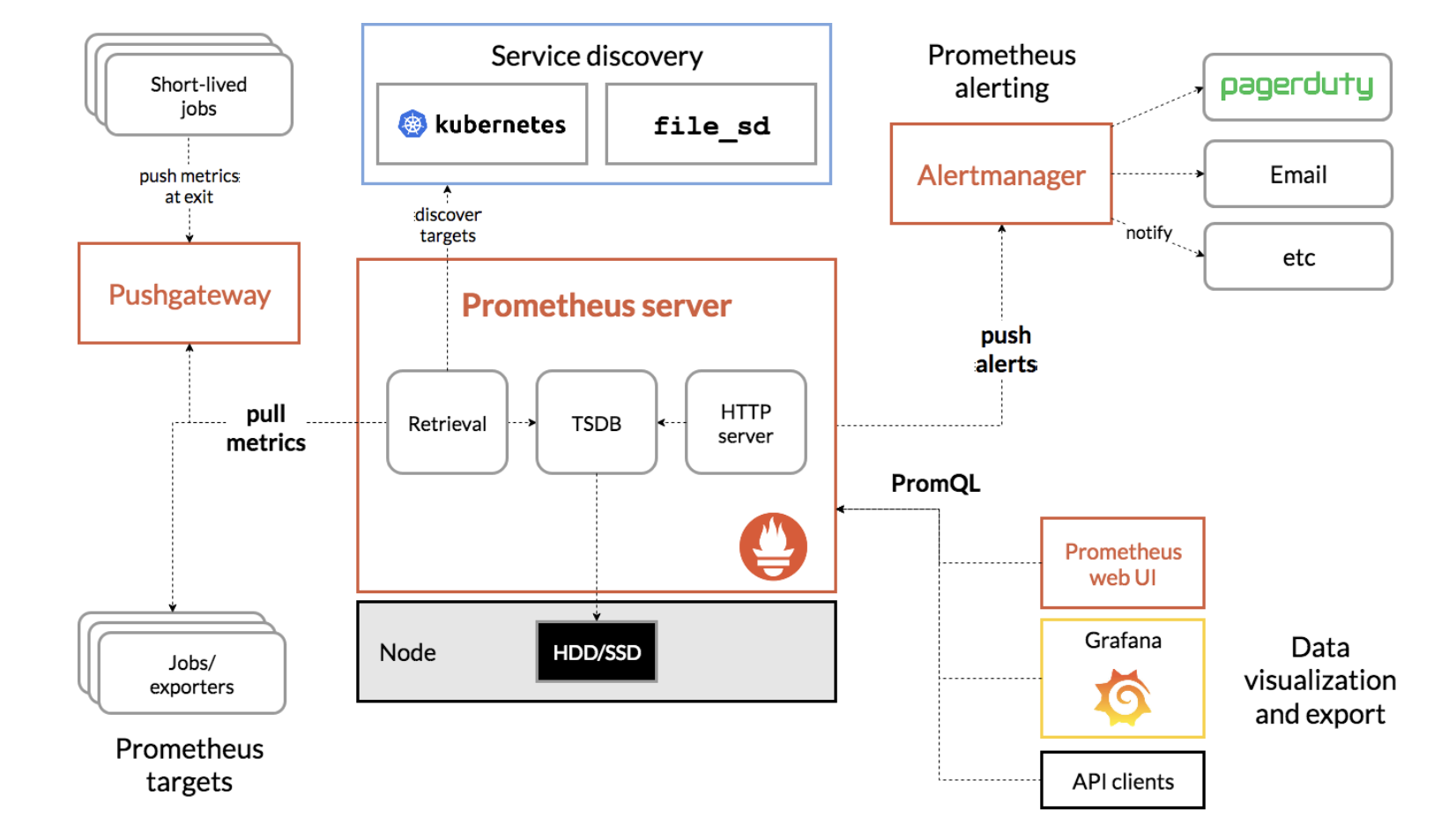
从架构图也可以看出 Prometheus 的主要模块包含,Server, Exporters, Pushgateway, PromQL, Alertmanager, WebUI 等。
各组件之间的协同逻辑:
- Prometheus server 定期从静态配置的 targets 或者服务发现的 targets 拉取数据。
- 当新拉取的数据大于配置内存缓存区的时候,Prometheus 会将数据持久化到磁盘(如果使用 remote storage 将持久化到云端)。
- Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert 推送到配置的 Alertmanager。
- Alertmanager 收到警告的时候,可以根据配置,聚合,去重,降噪,最后发送警告。
- 可以使用 API,Prometheus Console 或者 Grafana 查询和聚合数据。
什么是 Operator?
Operator 是 CoreOs 提出的一个概念,也是 SRE 的一种实践,通过开发软件的方式将复杂运维工作固化到 Operator 中。
Operator 是一种新的基于 Kubernetes 平台的软件类型,主要解决 Kubernetes 中某些复杂应用的运维部书工作,利用 Kubernetes 的 Resources 和 Controllers 两种资源对象实现 Operator,Resources 描述期望的目标状态,Controllers 负责达成期望目标的具体实现逻辑。
Prometheus Operator 介绍
Prometheus 是一套开源的系统监控、报警、时间序列数据库的组合,而 Prometheus Operator 是 CoreOS 开源的一套用于管理在 Kubernetes 集群上的 Prometheus 控制器,它是为了简化在 Kubernetes 上部署、管理和运行 Prometheus 和 Alertmanager 集群,同时还保持 Kubernetes 原生配置项,和 Kubernetes 无缝贴合。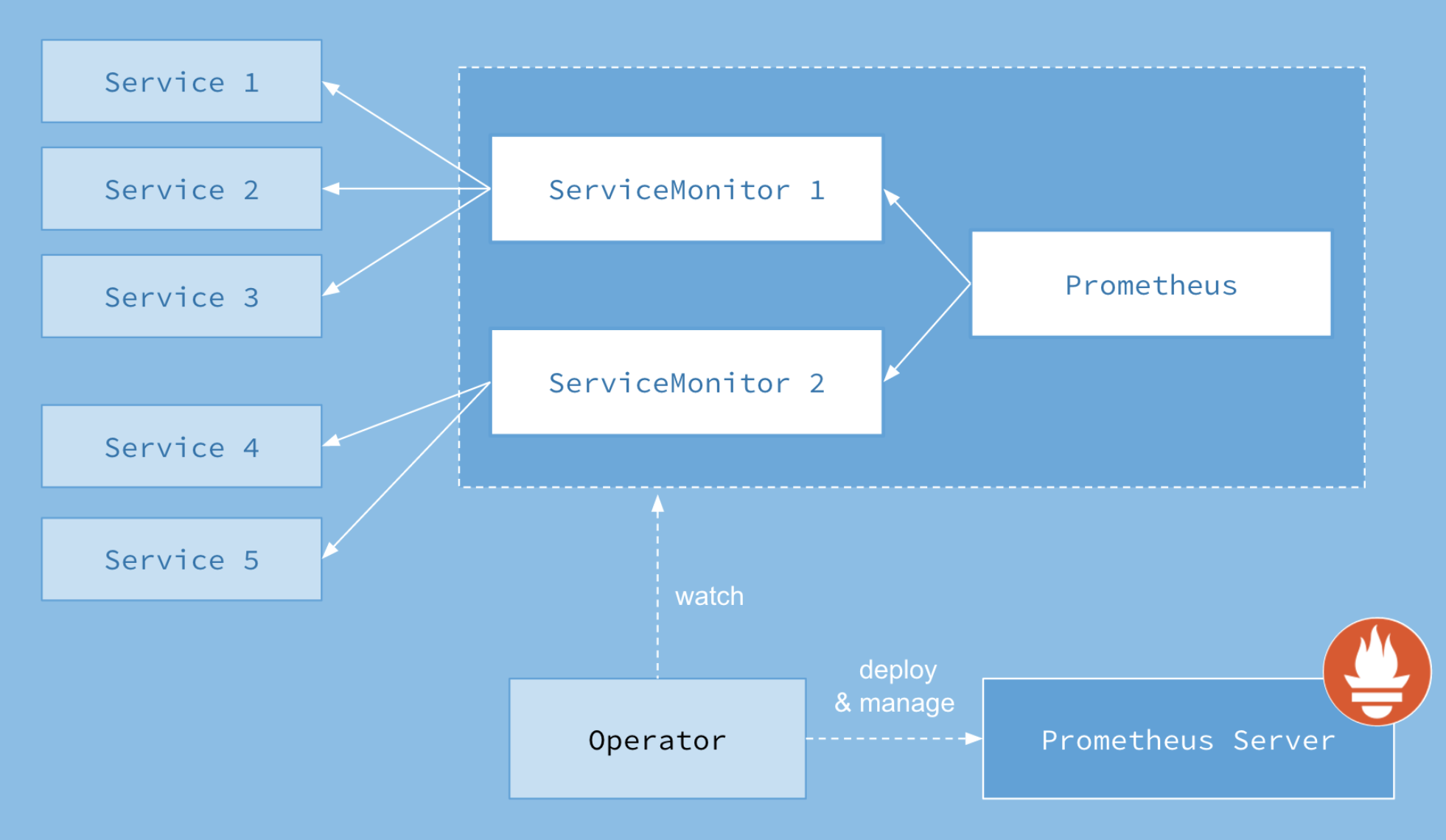
- Operator: Operator 资源会根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
- Prometheus: Prometheus 资源是声明性地描述 Prometheus 部署的期望状态。
- Prometheus Server: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群,这些自定义资源可以看作是用来管理 Prometheus Server 集群的 StatefulSets 资源。
- ServiceMonitor: ServiceMonitor 也是一个自定义资源,它描述了一组被 Prometheus 监控的 targets 列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。
- Service: kubernetes 的 service 资源,提供 metrics 接口,供 Prometheus 抓取。
- Alertmanager: Alertmanager 也是一个自定义资源类型,由 Operator 根据资源描述内容来部署 Alertmanager 集群。
Helm 部署 Prometheus Operator
使用 GitHub 提供的 prometheus-operator Chart 部署,该 Chart 提供了一套完整的 Prometheus 监控栈,不需要其他任何安装部署操作,一个 Chart 3 分钟搞定一切工作。1
helm install --name kube-prometheus stable/prometheus-operator --namespace monitoring
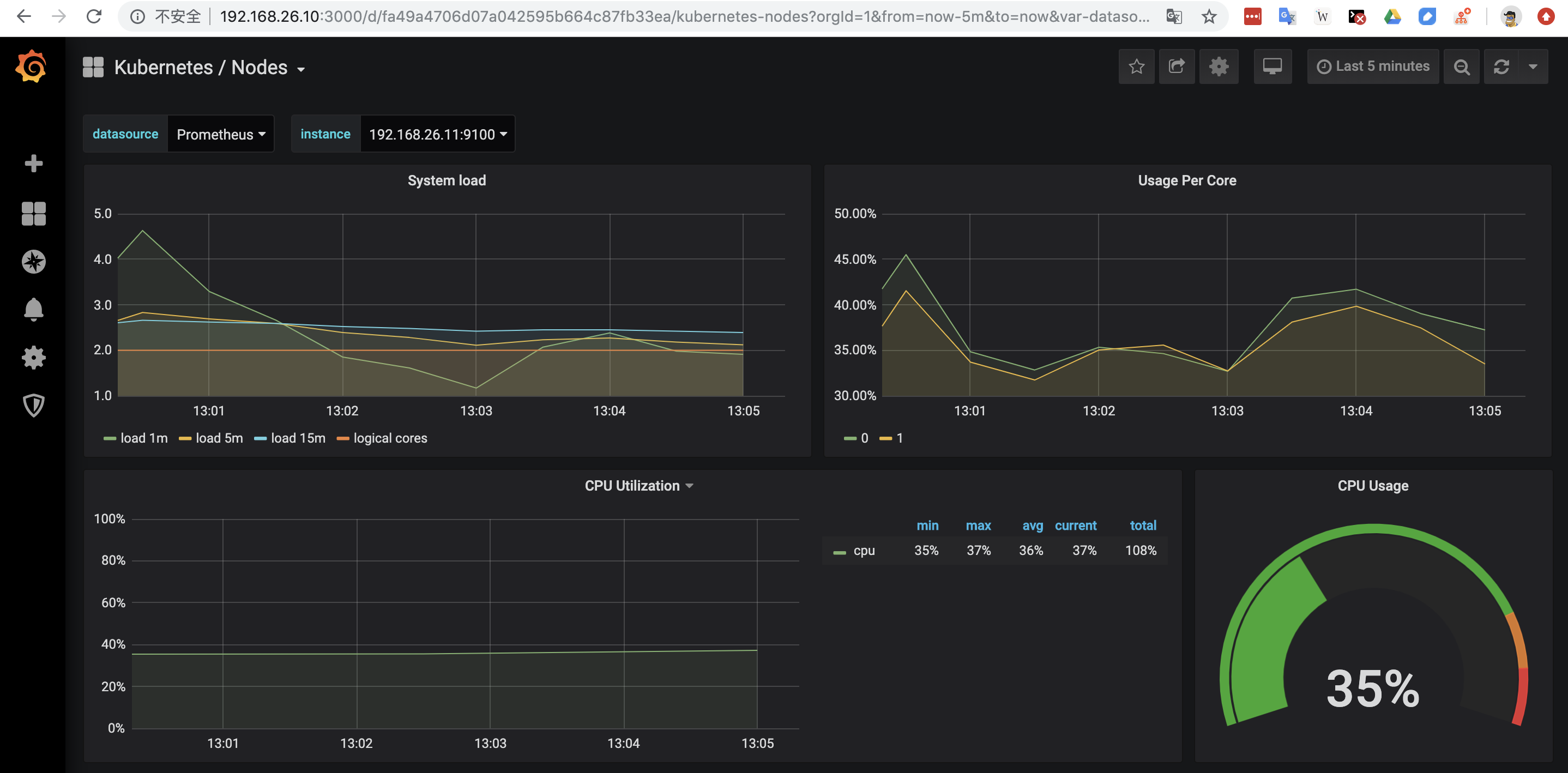
测试访问:
Grafana UI1
kubectl port-forward <grafna pod> --address 0.0.0.0 -n monitoring 3000:3000
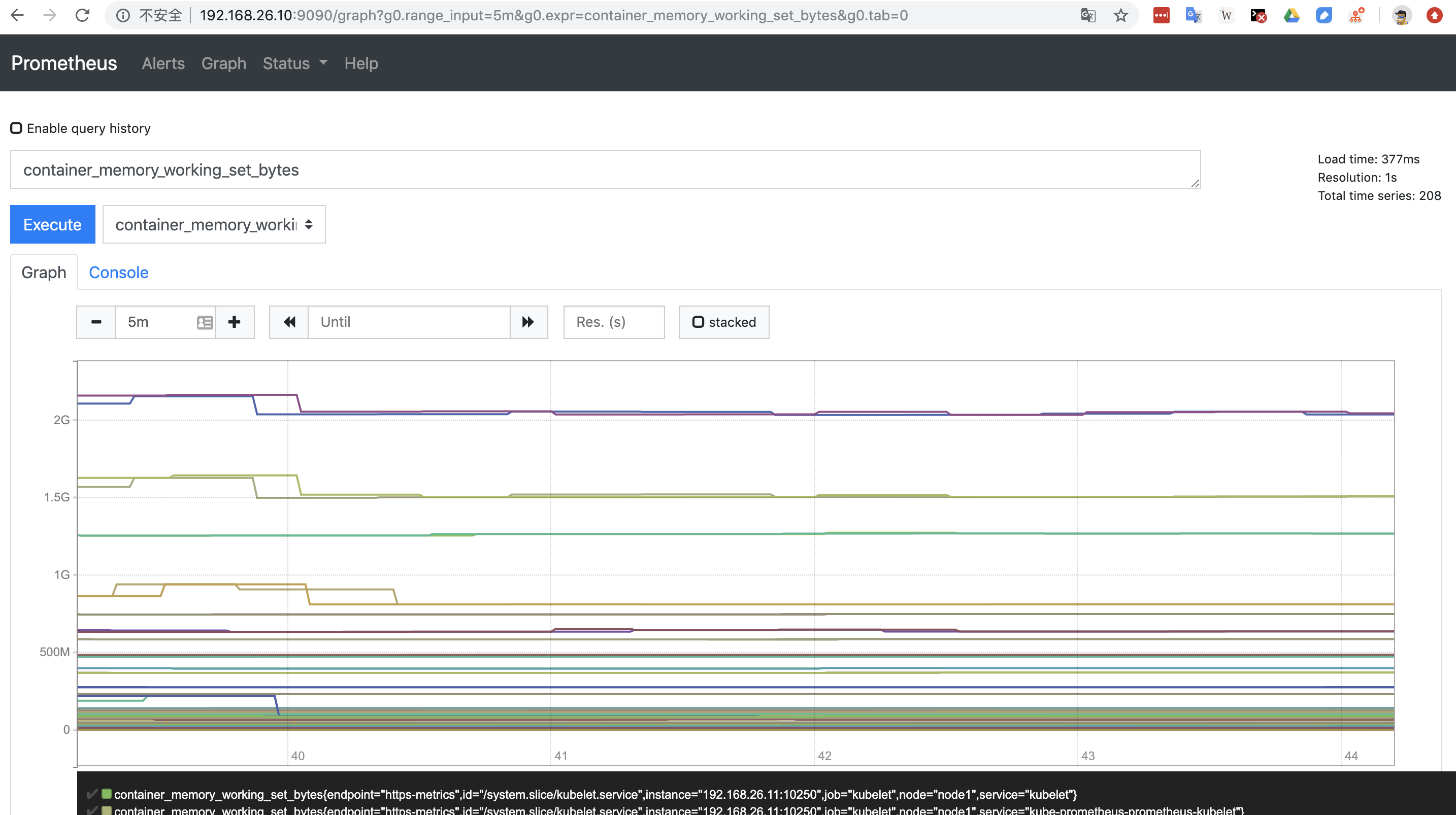
Prometheus UI1
kubectl port-forward <prometheus pod> --address 0.0.0.0 -n monitoring 9090:9090
参考文档
https://coreos.com/blog/the-prometheus-operator.html
https://github.com/coreos/kube-prometheus
https://github.com/coreos/prometheus-operator
https://blog.csdn.net/aixiaoyang168/article/details/81661459
https://blog.51cto.com/3241766/2450776
https://www.chenshaowen.com/blog/quickly-deploy-prometheus-using-helm-and-operator.html