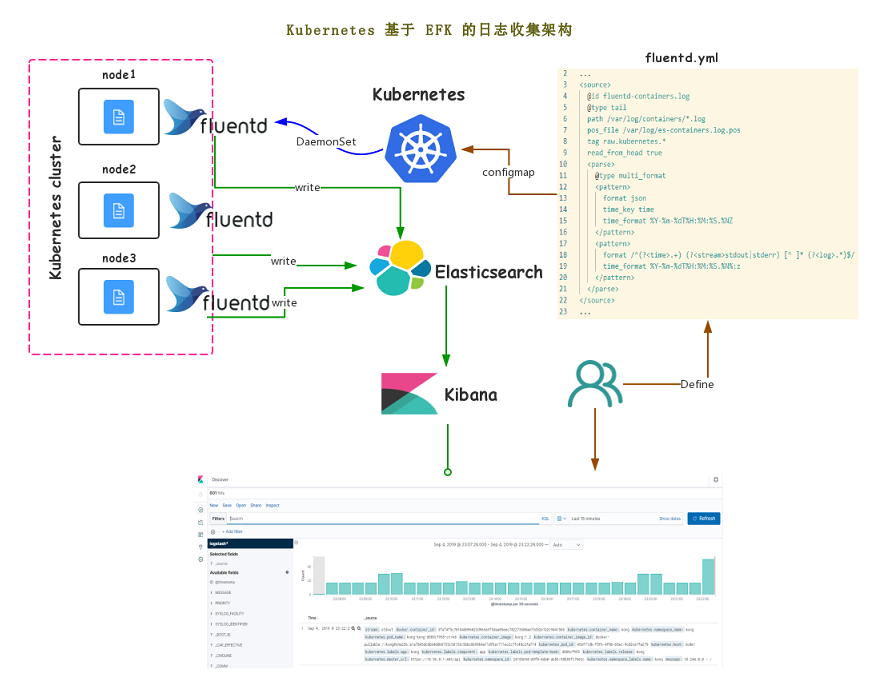
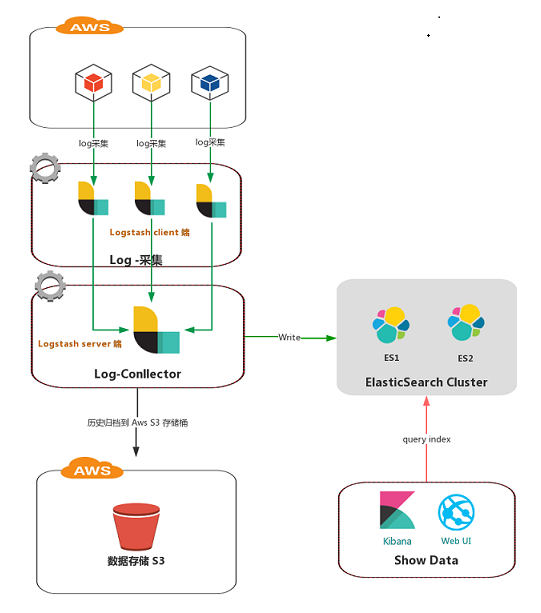
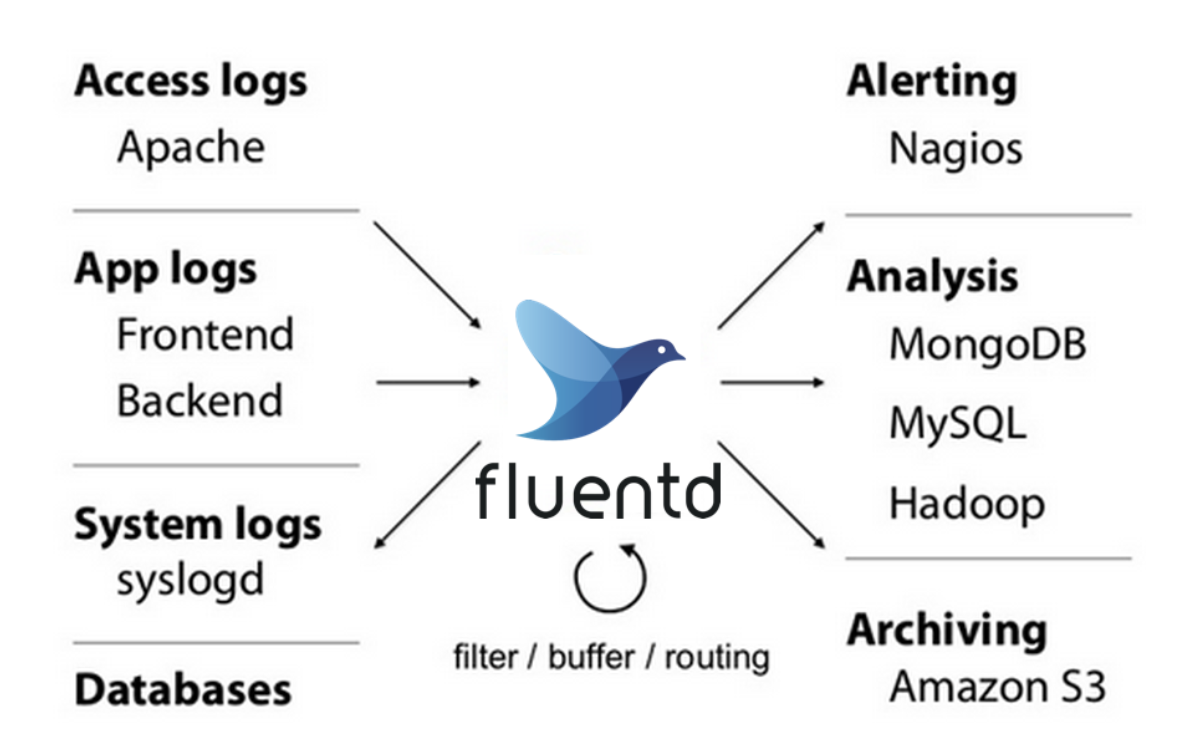
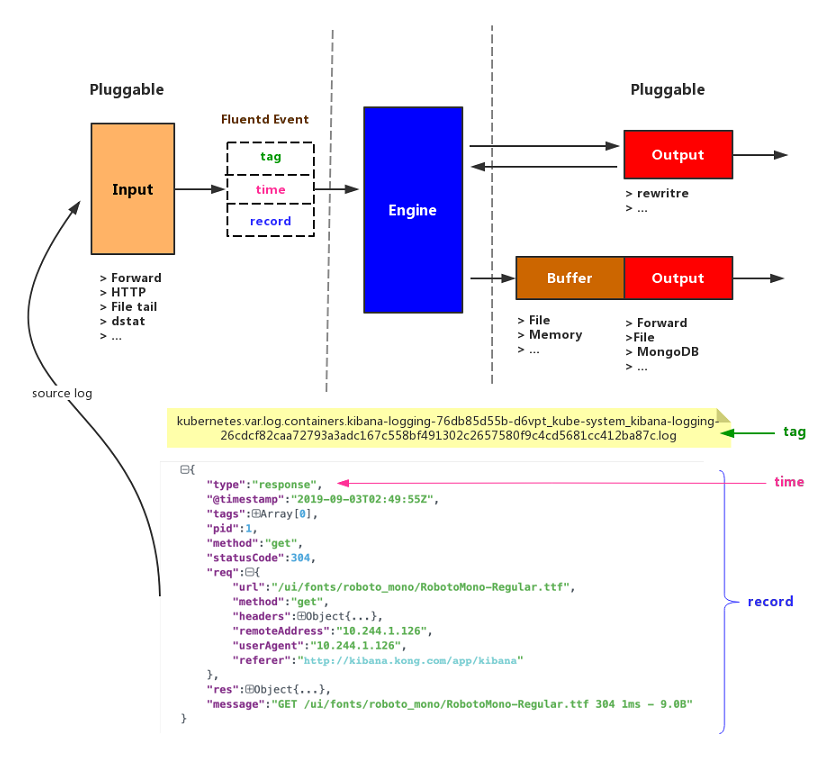
从 k8s v1.14 开始,官方已经废弃了 swagger 接口,使用 openapi 规范,暴露出来的接口是: /openapi/v2,我们要想通过
swagger-ui 来查看 apiserver 接口,可以自己本地跑个 swagger-ui 服务,然后访问 kube-apiserver 地址的 openapi 接口地址即可,swagger-ui 来源支持 openapi 数据格式。
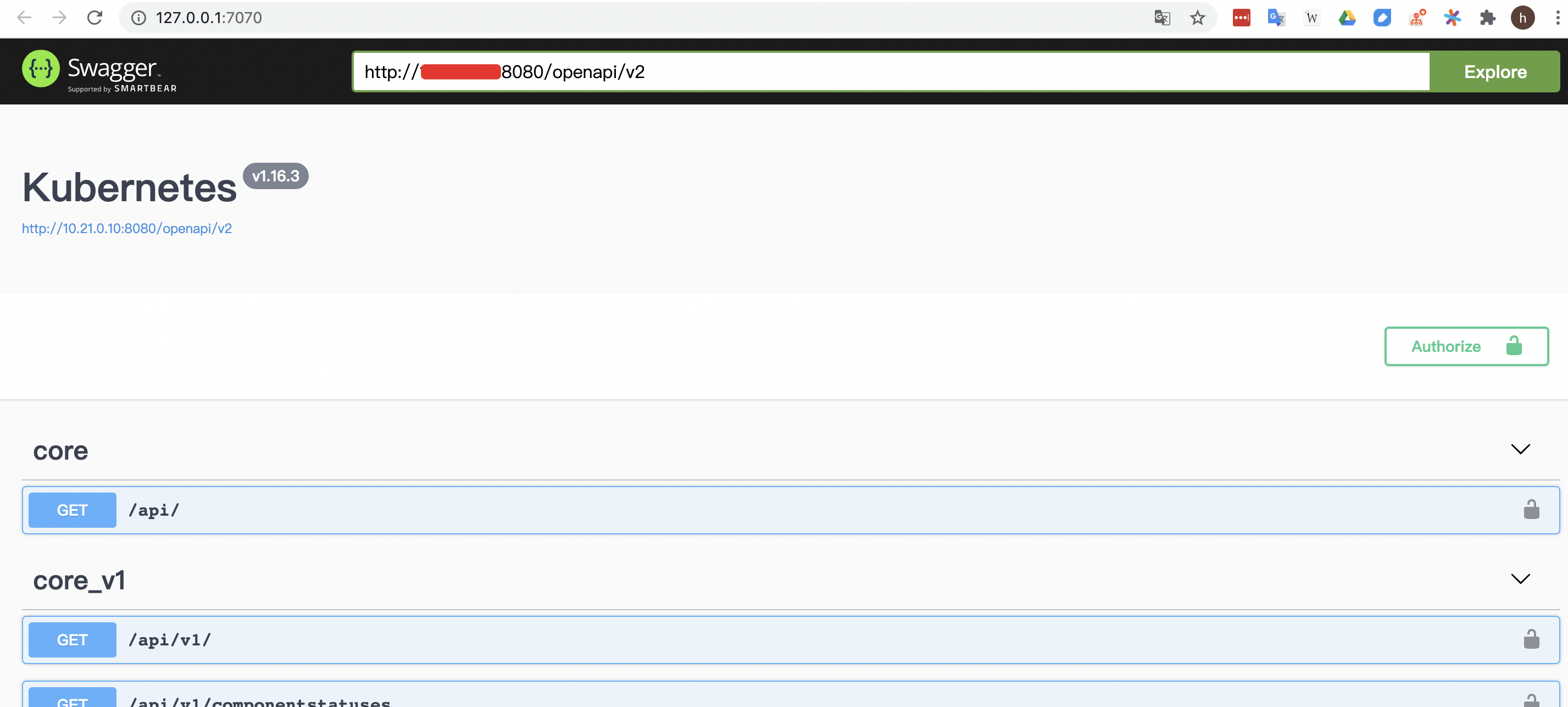
1.本地启动 swagger-ui 服务1
docker run --name swagger-ui --restart always -p 7070:8080 -d swaggerapi/swagger-ui:latest
2.访问 swagger-ui 地址 http://127.0.0.1:7070,输入 kube-apiserver 地址的 openapi 接口地址:http://kube-apiserver-ip:8080/openapi/v2
这里 openapi 地址是 kube-apiserver 的 http 地址,为了方便,如果是 https 比较麻烦,因为涉及到了 apiserver 的认证授权相关东西。所以为了方便本地调试,还是用 http 地址。
注意:直接访问存在跨域问题,需要安装 Chrome 的 Allow CORS 插件实现跨域访问,插件传送门:https://chrome.google.com/webstore/detail/allow-cors-access-control/lhobafahddgcelffkeicbaginigeejlf?hl=en
参考文档:
https://kubernetes.io/zh/docs/concepts/overview/kubernetes-api/
https://blog.schwarzeni.com/2019/09/16/Minikube%E4%BD%BF%E7%94%A8Swagger%E6%9F%A5%E7%9C%8BAPI/