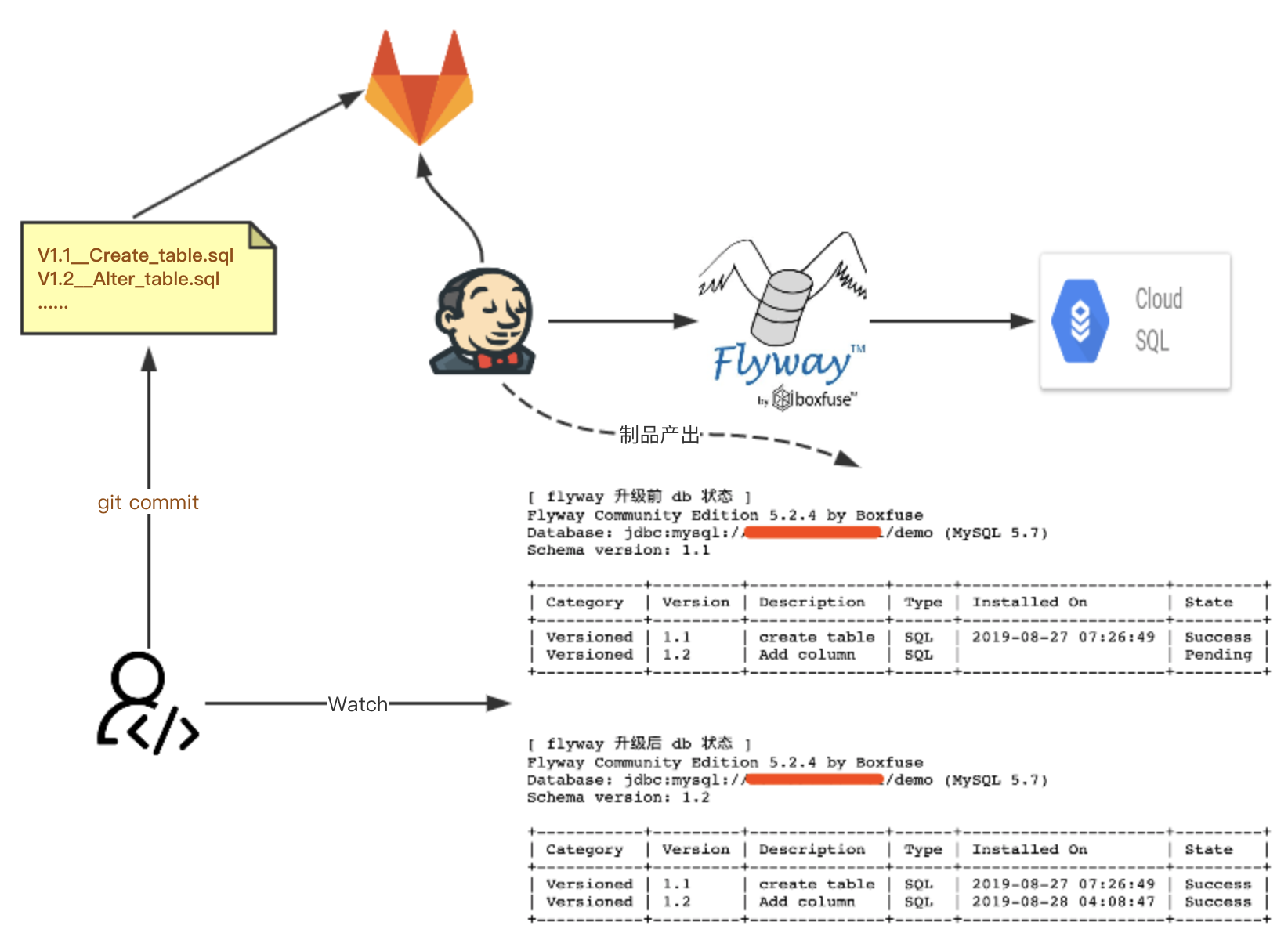
最近 Kubernetes 集群中出现过几次 Redis 故障,具体表现是每次集群重启(云资源按需启动), Redis Pod 都要老半天才能启动起来,后来逐渐排查定位才发现原来是由于 Redis 开启了 aof 持久化机制。
我们知道在 AOF 持久化机制下,Resdis 的每一条写命令都会被同步、并且追加的方式持久化的磁盘文件,当 Redis 由于意外故障时,下次重启就会原封不动地执行 AOF 文件中的命令来恢复 Redis。那么显然这种方式会带来一个问题是随着时间的推移 aof 文件体积会越来越大,每次 Redis 重启都要执行一遍 aof 持久化的命令,速度也会越来越慢,从而导致 Redis 启动变慢。
显然解决方法是怎么把 AOF 文件变小,丢弃没用的记录。Redis 有一条 BGREWRITE 命令就是解决这问题的,这条命令的工作原理是将当前 Redis 中的数据都导出成 Redis 写语句,然后生成新的 aof 文件,替换掉旧的。显然新的 aof 文件体积会原因小于长时间运行的旧的 aof 文件,因为新的 aof 只是当前 Redis 的数据恢复语句,只记录当前的状态。
由于我们 Redis 是运行在 Kubernetes 集群中,所以借助于 Kubernetes 的 CronJob 机制定期执行 Redis BGREWRITE 命令来重写 aof 文件,从而缩小文件体积。
Kubernetes CronJob 简介
Kubernetes CronJob 资源用来定义一些需要定时执行的任务,类似于 Linux/Unix 的 Crontab。CronJob 资源创建后会按照写的定时任务规则启动 Pod 执行定义的任务。关于 CronJob 更详细的信息见这里:https://kubernetes.io/docs/tasks/job/automated-tasks-with-cron-jobs
基于 k8s CronJob 定期 AOF 重写
定义 CronJob 资源文件,每两小时进行一次 Redis AOF 重写,资源文件如下:
redis-cron.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27apiVersion: batch/v1beta1 #for API server versions >= 1.8.0 use batch/v1beta1
kind: CronJob
metadata:
name: redis-bgrewriteaof-cron
labels:
app: redis-bgrewriteaof-cron
spec:
schedule: "0 */2 * * *"
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 3
concurrencyPolicy: Forbid
startingDeadlineSeconds: 120
jobTemplate:
spec:
template:
spec:
containers:
- name: redis
image: docker.io/bitnami/redis:4.0.12
env:
- name: REDIS_PASSWORD
valueFrom:
secretKeyRef:
name: redis-test
key: redis-password
args: [redis-cli, -h, redis-stage-master, -a, $(REDIS_PASSWORD), BGREWRITEAOF]
restartPolicy: OnFailure
关于上面资源里面的一些配置项含义在此不做具体介绍,很多都能看懂,具体每个配置项含义看官方文档,都有详细的解释。这里有一点需要「特别注意」的是 redis
容器的 args 字段引用环境变量的方法:
比如这里引用了 REDIS_PASSWORD 环境变量,需要写成:$(REDIS_PASSWORD) 这样的方式引用,而不能写成:$REDIS_PASSWORD 或者 ${REDIS_PASSWORD}。
执行 kubectl create 创建定义的 CronJob 资源1
kubectl create -f redis-cron.yaml -n test
查看 CronJob 执行情况1
2
3$ kubectl get cronjob -n test
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
redis-bgrewriteaof-cron 0 */2 * * * False 0 1h 14h
可以看出最近一小时前已经调度过一次,如果要看调度是否成功可以看对应 Pod 的 log,也可以 kubectl get jobs -n test 查看启动的 Job 的状态。
相关文档
https://kubernetes.io/docs/tasks/job/automated-tasks-with-cron-jobs | Running Automated Tasks with a CronJob
https://redis.io/commands/bgrewriteaof | Redis之AOF重写及其实现原理