简介
Supervisor 是一个用 Python 写的进程管理工具,可以很方便的用来启动、重启、关闭进程。类似于 Linux 的 systemd 守护进程一样,通过统一的命令来管理系统的各个服务,当管理的服务挂掉时会自动重新拉起。Supervisor 还提供了很多第三方插件,比如后面会讲到的 CeSi,该工具是 Supervisor 的 WebUI,可以通过这个统一的 WebUI 集中化管理各个服务器节点的进程。
Supervisor 和 Docker 的架构类似,也是 C/S 架构,服务端是 supervisord,客户端是 supervisorctl 。客户端主要是用来控制服务端所管理的进程,比如控制服务的启动、关闭、重启、查看服务状态,还可以重启服务端、重载配置文件等。服务端管控各个服务的正常运行,当有服务异常退出时会自动拉起。
Supervisor 的安装及基本使用
1. 安装
Supervisor 的安装特别简单,由于是 Python 写的,因此可以通过 pip 一键安装:1
pip install supervisor
在此我提供了一个 Sueprvisor 一键安装配置脚本,简化了 Supervisor 的初始配置。
2. 基本使用
安装完成后系统会多出如下三个命令:
supervisord:Supervisor 的服务端;supervisorctl:Supervisor 的客户端;echo_supervisord_conf:Supervisor 服务端默认配置文件生成工具;
2.1 启动 supervisor
首先通过如下命令将 supervisor 的默认配置生成到 /etc/supervisord.conf:1
echo_supervisord_conf > /etc/supervisord.conf
Supervisor 配置文件格式是 INI 格式,因此看起来比较直观,很多配置项的含义已在上面生成的配置文件中以注释的形式说明,以下简要说明一下我在生产环境目前使用的配置,为了减少篇幅,在此只列出了非注释的内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22[unix_http_server]
file=/tmp/supervisor.sock ; 服务端套接字文件路径,supervisorctl 客户端会使用该文件和服务端通信
[inet_http_server] ; Supervisor 服务端提供的 http 服务,很多 Supervisor 的 WebUI
;都是通过访问该服务来实现统一管理的,比如后面要讲的 CeSi Web UI
port=0.0.0.0:9001 ; ip_address:port specifier, *:port for all iface
[supervisord] ; Supervisor 服务端配置
logfile=/tmp/supervisord.log ; 服务端日志文件路径
logfile_maxbytes=50MB ; max main logfile bytes b4 rotation; default 50MB
logfile_backups=10 ; # of main logfile backups; 0 means none, default 10
loglevel=debug ; log level; default info; others: debug,warn,trace
pidfile=/tmp/supervisord.pid ; supervisord pidfile; default supervisord.pid
nodaemon=false ; start in foreground if true; default false
minfds=1024 ; min. avail startup file descriptors; default 1024
minprocs=200 ; min. avail process descriptors;default 200
user=root
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl] ; Supervisor 客户端配置
serverurl=unix:///tmp/supervisor.sock ; 配置客户端和服务端的通信方式,默认 supervisorctl
;和 supervisor 通信是通过该套接字通信,也可以配成通过 http 方式通信。
[include] ; 在此我将 Supervisor 所管理的服务配置文件都放到了 /etc/supervisor/ 目录,然后通过 include 统一引入
files = /etc/supervisor/*.conf
接下来在 /etc/supervisor/ 放入需要 Supervisor 管理的各服务的配置文件,一般一个服务一个配置文件,当然也可以写到一起,比如逻辑上有关联的一组服务可以放到一个配置文件,这样方便管理,下面以一个实例来介绍下要通过 Supervisor 管理服务,相应的配置文件该如何编写(使用 Supervisor 管理 cesi 服务的配置):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15; cesi.conf
[program:cesi-5000] ; program 表示 Supervisor 管理的服务实例,cesi-5000 是自己命名
;的服务名称,名字可以随便其,我为了方便管理统一命名为:服务名称-端口
directory = /home/ec2-user/cesi ; 程序的启动目录
command = python cesi/web.py ; 启动服务的命令
autostart = true ; 在 supervisord 启动的时候也自动启动
startsecs = 5 ; 启动 5 秒后没有异常退出,就当作已经正常启动了
autorestart = true ; 程序异常退出后自动重启
startretries = 3 ; 启动失败自动重试次数,默认是 3
user = ec2-user ; 用哪个用户启动
redirect_stderr = true ; 把 stderr 重定向到 stdout,默认 false
stdout_logfile_maxbytes = 50MB ; stdout 日志文件大小,默认 50MB
stdout_logfile_backups = 7 ; stdout 日志文件备份数
; stdout 日志文件,需要注意当指定目录不存在时无法正常启动,所以需要手动创建目录(supervisord 会自动创建日志文件)
stdout_logfile = /home/ec2-user/cesi/stdout.log
将上述配置保存为 cesi.conf,放到 /etc/supervisor/。
前面已经对 echo_supervisord_conf 生成的默认配置文件做了微调,接下来启动 Supervisor 服务端(建议用 root 用户启动):1
sudo supervisord -c /etc/supervisord.conf
如果不指定 -c 参数,会通过如下顺序来搜索配置文件:1
2
3
4$PWD/supervisord.conf
$PWD/etc/supervisord.conf
/etc/supervisord.conf
/etc/supervisor/supervisord.conf
2.2 Supervisor 客户端 supervisorctl
supervisorctl 有两种使用方式:
一种是直接执行 supervisorctl ,这样会进入交互式的 Shell, 然后在该交互式 Shell 中输入管理命令,举例:1
2
3
4
5
6[root@awsuw supervisor]# supervisorctl
cesi-5000 RUNNING pid 6538, uptime 1 day, 1:21:02
zipkinstage-9411 RUNNING pid 30919, uptime 1 day, 19:51:43
supervisor> status
cesi-5000 RUNNING pid 6538, uptime 1 day, 1:21:09
zipkinstage-9411 RUNNING pid 30919, uptime 1 day, 19:51:50
另一种是 supervisorctl [action] 的方式,这样不会陷入交互式 Shell,直接会返回命令的执行结果,其中 action 就是管理服务进程的各个命令,举例(查看目前所管理的服务的进程状态):1
2
3[root@awsuw supervisor]# supervisorctl status
cesi-5000 RUNNING pid 6538, uptime 1 day, 1:24:53
zipkinstage-9411 RUNNING pid 30919, uptime 1 day, 19:55:34
其中常用的 action 有如下(更多选项参数见 这里):
supervisorctl status: 查看所管理的服务状态;supervisorctl start <program_name>:启动一个服务;supervisorctl restart <program_name>:重启一个服务(注意:重启服务不会重新加载配置文件);supervisorctl stop <program_name>:关闭一个服务;supervisorctl update:重新加载配置文件,并重启配置有变动的服务;supervisorctl reread:重新加载配置文件,但不会重启配置有变动的服务;supervisorctl reload:重启Supervisor服务端;supervisorctl clear <program_name>:清理一个服务的stdout log;
安装配置 CeSi
1. 简介
CeSi 是 Supervisor 官方推荐的集中化管理 Supervisor 实例的 Web UI,该工具是用 Python 编写,基于 Flask Web 框架 。
Superviosr 自带的 Web UI 不支持跨机器管理Supervisor 进程,功能比较简单,通过 CeSi 可以集中管理各个服务器节点的进程,在 Web 界面就可以轻松管理各个服务的启动、关闭、重启等,很方便使用。
2. 安装
安装 CeSi 有三个依赖:Python,Flask,sqlite3
一般的 Linux 发行版都默认安装了 Python,所以 Python 不需要再次安装;
从 Python 2.5 开始 sqlite3 已经在标准库内置了,所以也不需要安装 sqlite3 模块了;
另外很多 Linux 发行版已经自带 sqlite3,所以无需另外安装;
只需要安装 flask web 框架即可;
CeSi 已经有了新的版本,在 GitHub 仓库的 v2_api 分支下,提供了比之前版本更加美观的界面,以下为 CeSi 一键安装配置脚本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# !/bin/bash
set -e
sudo pip install flask
git clone https://github.com/gamegos/cesi.git
cd cesi
# 使用最新版, 最新版的 Web UI 做了很大改动
git checkout -b v2_api origin/v2_api
sudo cp cesi.conf.sample /etc/cesi.conf
sudo ln -s /etc/cesi.conf cesi.conf
#创建用户信息表:
sqlite3 userinfo.db < userinfo.sql
#CeSi log 目录
sudo mkdir -p /var/logs/cesi
sudo chmod 777 -R /var/logs
exit 0
注意:CeSi 的配置文件路径必须是 /etc/cesi.conf ,否则启动会报错,简单看下 CeSi 的源码就知道为什么了。在这里我在仓库目录弄了个软连接指向了 /etc/cesi.conf,完全是为了编辑方便弄的。
3. 配置
CeSi 的配置非常简单,和 Supervisor 的配置文件类似,也是 INI 格式,关于配置文件的各项说明在 cesi.conf.sample 配置样例中已经通过注释的形式给了明确的说明,稍微看下就能明白,以下为我目前使用的配置(为了减小篇幅,去掉了注释):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23[node:node1] ;各 Supervisor 节点的配置
username = ; 如果 Supervisor 节点没有设置账号密码,这里就保持为空,但不能不写
password =
host = 127.0.0.1
port = 9001
[node:node2]
username =
password =
host = node2.d.com
port = 9001
[node:node3]
username =
password =
host = node3.d.com
port = 9001
[cesi] ; CeSi 自身的配置
database = userinfo.db
activity_log = /var/logs/cesi/activity.log ;log目录没有的话需要提前建好
host = 0.0.0.0
port = 5000 ; CeSi 启动端口
name = CeSI
theme = superhero
4. 启动
CeSi 的启动非常简单,直接通过 Python 启动即可:1
python cesi/web.py
为了方便管理,我把 CeSi 也通过 Supervisor 来管理,以下为对应的 Supervisor 配置:1
2
3
4
5
6
7
8
9
10
11
12
13
14;cesi.conf
[program:cesi-5000]
directory = /home/ec2-user/cesi ; 程序的启动目录
command = python cesi/web.py
autostart = true ; 在 supervisord 启动的时候也自动启动
startsecs = 5 ; 启动 5 秒后没有异常退出,就当作已经正常启动了
autorestart = true ; 程序异常退出后自动重启
startretries = 3 ; 启动失败自动重试次数,默认是 3
user = ec2-user ; 用哪个用户启动
redirect_stderr = true ; 把 stderr 重定向到 stdout,默认 false
stdout_logfile_maxbytes = 50MB ; stdout 日志文件大小,默认 50MB
stdout_logfile_backups = 7 ; stdout 日志文件备份数
; stdout 日志文件,需要注意当指定目录不存在时无法正常启动,所以需要手动创建目录(supervisord 会自动创建日志文件)
stdout_logfile = /home/ec2-user/cesi/stdout.log
启动完成后,做个 Nginx 反向代理即可通过浏览器访问,最终效果如下: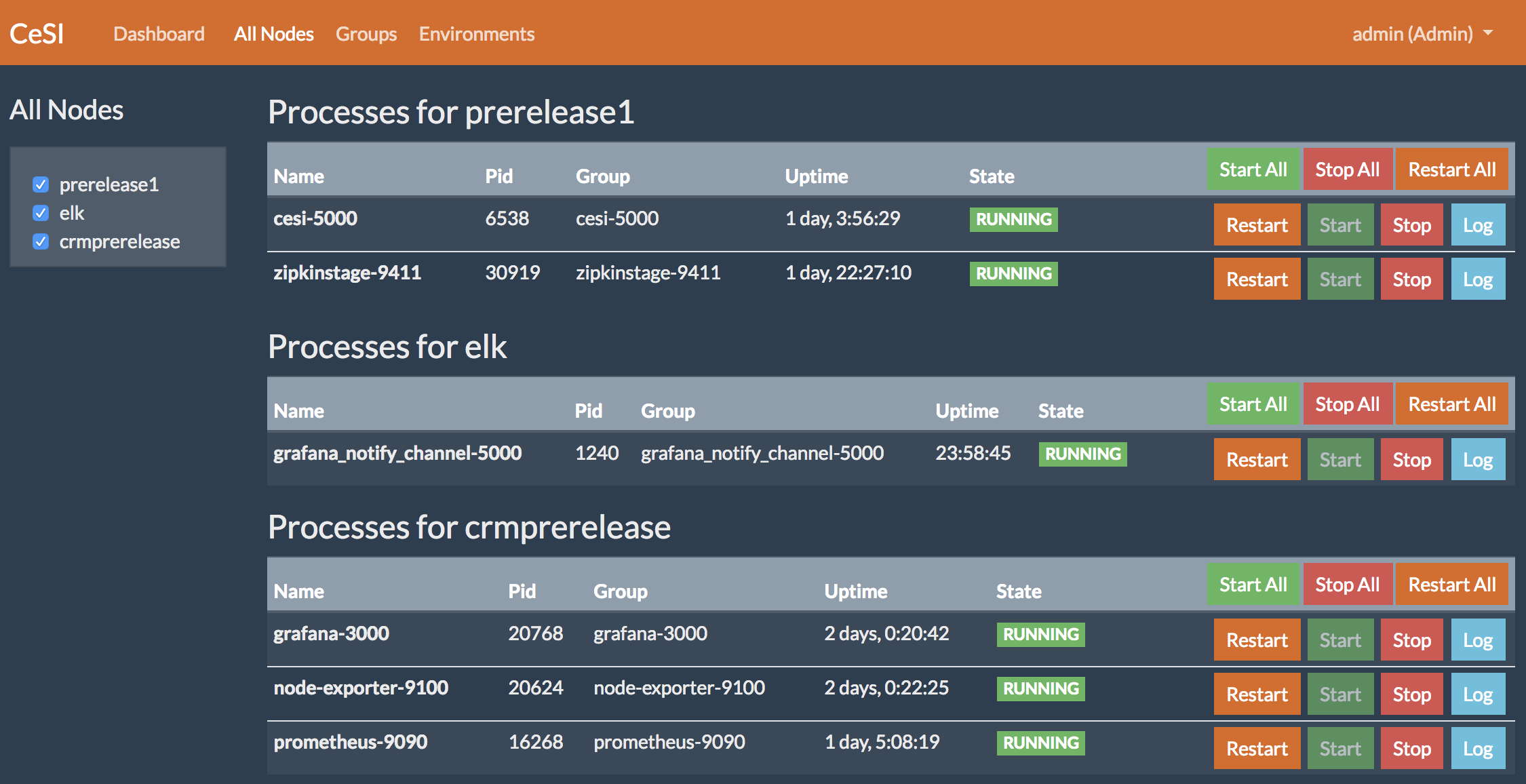
Supervisor 服务设置开机自启动
以下为在 RedHat7下配置 Supervisor 开机自启动过程,编写 Unit 文件,使用 systemd 管理 Supervisor:
编写
Unit文件:supervisord.service:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#supervisord.service
[Unit]
Description=Supervisor daemon
[Service]
Type=forking
ExecStart=/bin/supervisord -c /etc/supervisord.conf
ExecStop=/bin/supervisorctl shutdown
ExecReload=/bin/supervisorctl -c /etc/supervisord.conf reload
KillMode=process
Restart=on-failure
RestartSec=42s
[Install]
WantedBy=multi-user.target将上述文件拷贝到
/usr/lib/systemd/system/目录下将
supervisor.service注册到系统中1
2[root@awsuw ~]# systemctl enable supervisord.service
Created symlink from /etc/systemd/system/multi-user.target.wants/supervisord.service to /usr/lib/systemd/system/supervisord.service.可以看出注册过程就是在
/etc/systemd/system/multi-user.target.wants/目录下创建一个软链接指向第二步中的中拷贝到/usr/lib/systemd/system/的文件。
参考链接
http://supervisord.org/index.html
http://www.bjhee.com/supervisor.html
https://www.jianshu.com/p/03619bf7d7f5
http://liyangliang.me/posts/2015/06/using-supervisor