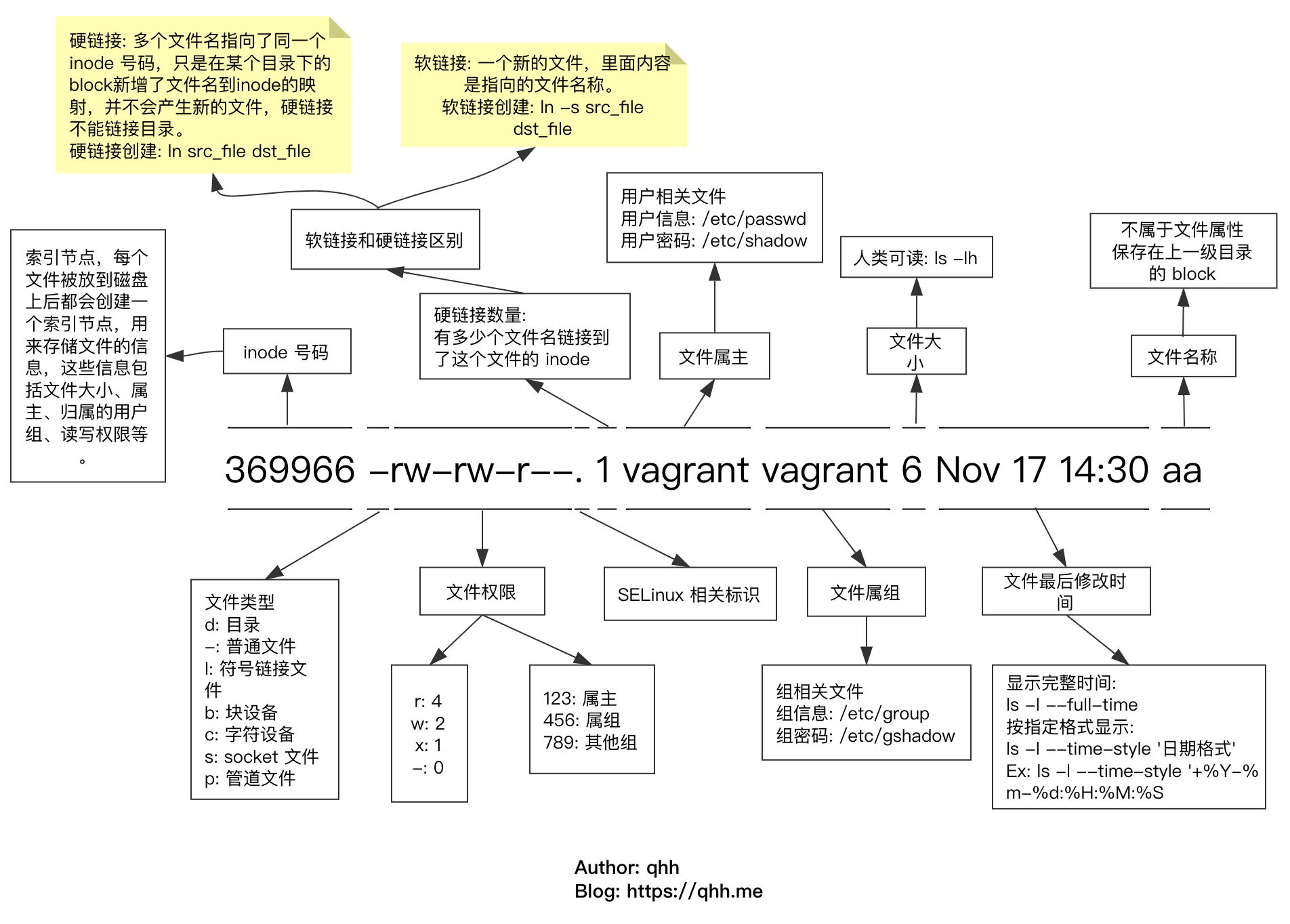
问题描述
有时候我们需要对 gcs 开启日志记录功能,一方面可以分析统计每个针对 gcs 的 http 请求的详细信息,另一方面还可以用于问题调试用途,比如我们对一个存储分区的对象配置了生命周期,可以看其访问日志判断配置是否生效。
gcs 日志记录功能记录两种类型日志
访问日志:访问日志是每小时创建一次,记录对指定存储分区发出的所有请求的信息;
存储日志:存储分区过去 24 小时内存储空间平均使用量,以字节为单位;
https://cloud.google.com/storage/docs/access-logs?hl=zh-cn&refresh=1
gcs 开启日志记录功能步骤
以开启 gs://gcs-bucket 存储分区日志记录功能为例:
创建一个存储分区用于存储日志记录,名字随便起:
1
gsutil mb -l asia gs://gcs-bucket-logs-record
设置权限以使 Cloud Storage 对该存储分区具有 WRITE 权限
1
gsutil acl ch -g cloud-storage-analytics.com:W gs://gcs-bucket-logs-record
为存储分区开启日志记录功能
命令格式:gsutil logging set on -b <日志存储分区> <要开启日志记录功能的存储分区>1
gsutil logging set on -b gs://gcs-bucket-logs-record gs://gcs-bucket
检查日志记录功能是否开启成功
1
gsutil logging get gs://gcs-bucket
如果开启成功会显示:
{"logBucket": "gcs-bucket-logs-record", "logObjectPrefix": "gcs-bucket"}另外,开启成功后过 2 小时左右就可以在 gs://gcs-bucket-logs-record 看到日志文件产生了,日志文件格式为 csv。
关闭日志记录功能
1
gsutil logging set off gs://gcs-bucket
日志文件命名格式及日志内容格式见文档详细说明
https://cloud.google.com/storage/docs/access-logs?hl=zh-cn&refresh=1